In the “Attention is All You Need” paper, the authors introduced the self-attention mechanism within the encoder-decoder architecture for building translation models. This guide provides a step-by-step tutorial on constructing a translation model using the Transformer architecture. We will code the encoder and decoder, train the model, save checkpoints, and perform inference. This post offers a comprehensive, hands-on approach to building a translation model with the Transformer.
The transformer model architecture was proposed in the paper:
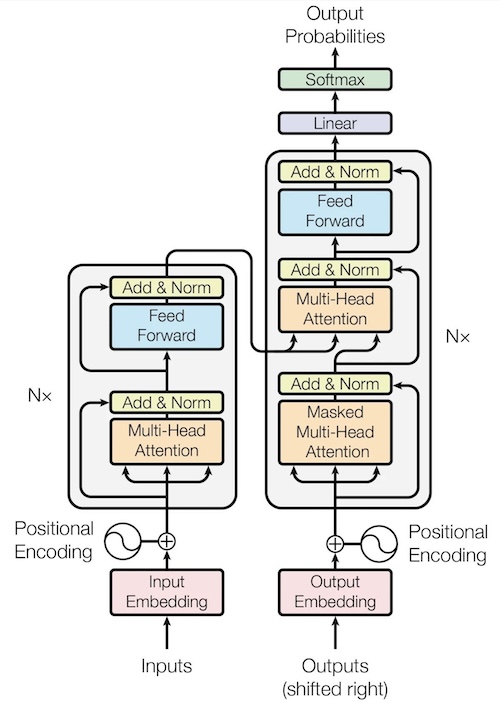
Encoder
The encoder’s purpose is to obtain the best contextual representation for the source language. It consists of multiple layers, and the input goes through these layers multiple times to yield optimal results. This iterative process allows the encoder to capture the nuances and dependencies within the source language. On the left side in the red circle is the encoder layer:
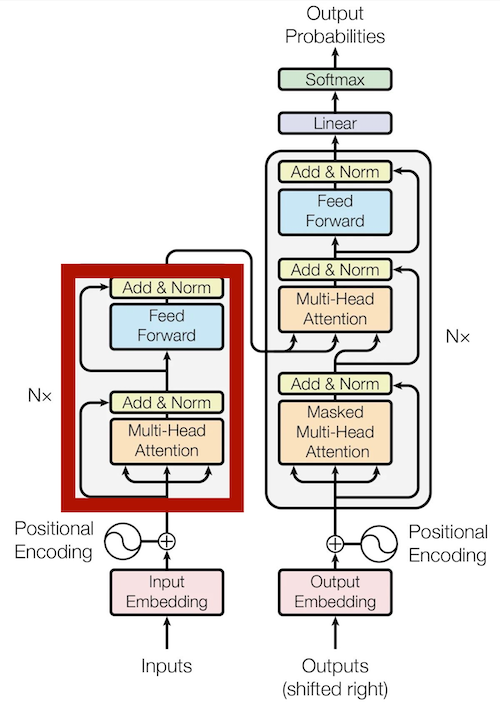
Positional Encoding
Before we dive into the encoder layers. Lets take a look at embedding and positional encoding. In simple terms, we need to mark the position of each token to understand the context. After all, ‘I love you’ and ‘You love me’ are very different statements - just ask anyone who’s ever mixed them up in a text message! Why do we use sinusoidal positional encoding you may ask? please check this article for reference: https://arxiv.org/pdf/2106.02795
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len = 5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, input):
input = input + self.pe[:, :input.size(1)].detach()
return self.dropout(input
Token embedding
Consider token embedding as a way to represent each token in a high-dimensional space. Each token is assigned a unique vector representation, which encodes its semantic and syntactic properties. By learning these embeddings during the training process, the model can capture the relationships and similarities between different tokens. The token embeddings are typically initialized randomly and then learned and updated during the training process. Heres the code for token embedding:
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, d_model, max_len=5000):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.max_len = max_len
def forward(self, input):
# Truncate or pad the input sequences to max_len
input = input[:, :self.max_len]
return self.embedding(input
Self-Attention and Multi-head Attention
As the model processes each word in the input sequence, self-attention focuses on all the words in the entire input sequence, helping the model encode the current word better. During this process, the self-attention mechanism integrates the understanding of all relevant words into the word being processed. More specifically, its functions include: Self-attention:
- Sequence Modeling: Self-attention can be used for modeling sequence data (such as text, time series, audio, etc.). It captures dependencies at different positions within the sequence, thus better understanding the context. This is highly useful for tasks like machine translation, text generation, and sentiment analysis.
- Parallel Computation: Self-attention allows for parallel computation, which means it can be effectively accelerated on modern hardware. Compared to sequential models like RNNs and CNNs, it is easier to train and infer efficiently on GPUs and TPUs (because scores can be computed in parallel in self-attention).
- Long-Distance Dependency Capture: Traditional recurrent neural networks (RNNs) may face issues like vanishing or exploding gradients when processing long sequences. Self-attention handles long-distance dependencies better because it doesn’t require sequential processing of the input sequence.
- Multi-head attention:
- Enhanced Ability to Focus on Different Positions: Multi-head attention extends the model’s ability to focus on different positions within the input sequence.
- Multiple Sets of Query/Key/Value Weight Matrices: There are multiple sets of query, key, and value weight matrices (Transformers use eight attention heads), each randomly initialized and the weights will be learned in the training process.
class ScaledProductAttn(nn.Module):
def __init__(self, dropout = 0.1):
super(ScaledProductAttn, self).__init__()
self.dropout = nn.Dropout(p=dropout)
self.softmax = nn.Softmax(dim=-1)
def forward(self, query, key, value, attn_mask = None):
_, _, _, d_k= query.shape
assert d_k != 0
attn = torch.matmul(query, key.transpose(-1, -2)) / np.sqrt(d_k)
if attn_mask is not None:
attn = attn.masked_fill(attn_mask == False, float('-inf'))
attn = self.dropout(self.softmax(attn))
context = torch.matmul(attn, value)
return contex
class MultiHeadAttn(nn.Module):
def __init__(self, n_head, d_model,dropout = 0.1):
super(MultiHeadAttn, self).__init__()
self.Q = nn.Linear(d_model, d_model)
self.K = nn.Linear(d_model, d_model)
self.V = nn.Linear(d_model, d_model)
self.n_head = n_head
self.scaled_dot_attn = ScaledProductAttn(dropout)
self.dropout = nn.Dropout(p = dropout)
self.norm = nn.LayerNorm(d_model)
def forward(self, x, attn_mask=None):
batch_size, seq_len, d_model = x.shape
h_dim = d_model // self.n_head
assert h_dim * self.n_head == d_model
Q = self.Q(x).view(batch_size, seq_len, self.n_head, h_dim).permute(0,2,1,3)
K = self.K(x).view(batch_size, seq_len, self.n_head, h_dim).permute(0,2,1,3)
V = self.V(x).view(batch_size, seq_len, self.n_head, h_dim).permute(0,2,1,3)
# print(f"the shape of Q: {Q}")
# print(f"the shape of K: {K}")
# print(f"the shape of V: {V}")
# print(f"attn_mask shape: {attn_mask.shape}")
if attn_mask is not None:
attn_mask = attn_mask.expand(batch_size, self.n_head, seq_len, seq_len) # Expanding to [batch_size, n_head, seq_len, seq_len]
# print(f"attn_mask shape after expansion: {attn_mask.shape}")
attn_score = self.scaled_dot_attn(Q, K, V, attn_mask)
attn_score = attn_score.permute(0,2,1,3).reshape(batch_size, seq_len, -1)
attn_score = self.dropout(attn_score)
attn_score = self.norm(attn_score + x)
return attn_score
We put everything togther, this is the code for the encoder layer
class EncoderLayer(nn.Module):
"""
multi-head attention
feedforward network
normalization layers
regularization
"""
def __init__(self, n_head, d_model, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.multiheadattn = MultiHeadAttn(n_head, d_model, dropout)
self.fnn = PoswiseFeedForwardNet(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, attn_mask):
x = self.norm1(x)
attn_output = self.multiheadattn(x, attn_mask)
x = x + self.dropout(attn_output)
x = self.norm2(x)
ff_output = self.fnn(x)
x = x + self.dropout(ff_output)
return x
Decoder
The decoder is a crucial component in the Transformer architecture, responsible for generating the translated tokens in the target language. Its main objective is to capture the dependencies and relationships among the translated tokens while utilizing the representations from the encoder. The decoder operates by first performing self-attention on each of the translated tokens in the source language. This self-attention mechanism allows the decoder to consider the context and dependencies within the translated sequence itself. By attending to its own previous outputs, the decoder can generate more coherent and contextually relevant translations. The red circlec is the decoder part of the architecture:
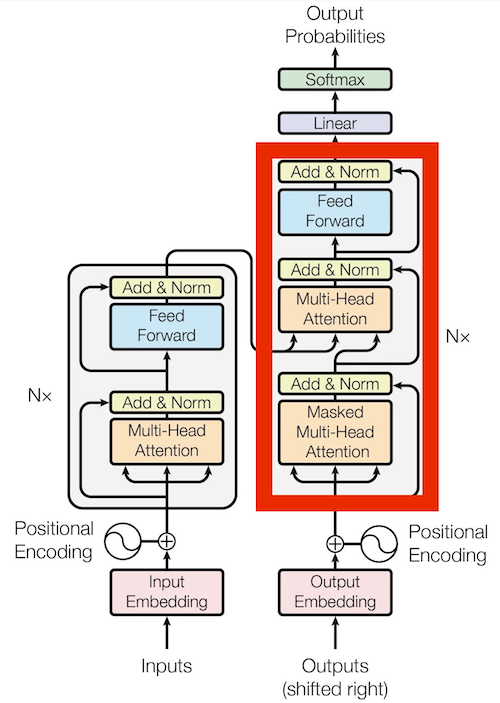
The decoder architecture consists of several key components, including multi-head self-attention, cross-attention, normalization, and regularization techniques. These components work together to enable the decoder to effectively capture the nuances and dependencies in the target language.
Masked Multi-Head attention
We shared the multi-head attention class with the encoder:
class ScaledProductAttn(nn.Module):
def __init__(self, dropout = 0.1):
super(ScaledProductAttn, self).__init__()
self.dropout = nn.Dropout(p=dropout)
self.softmax = nn.Softmax(dim=-1)
def forward(self, query, key, value, attn_mask = None):
_, _, _, d_k= query.shape
assert d_k != 0
attn = torch.matmul(query, key.transpose(-1, -2)) / np.sqrt(d_k)
if attn_mask is not None:
attn = attn.masked_fill(attn_mask == False, float('-inf'))
attn = self.dropout(self.softmax(attn))
context = torch.matmul(attn, value)
return context
class MultiHeadAttn(nn.Module):
def __init__(self, n_head, d_model,dropout = 0.1):
super(MultiHeadAttn, self).__init__()
self.Q = nn.Linear(d_model, d_model)
self.K = nn.Linear(d_model, d_model)
self.V = nn.Linear(d_model, d_model)
self.n_head = n_head
self.scaled_dot_attn = ScaledProductAttn(dropout)
self.dropout = nn.Dropout(p = dropout)
self.norm = nn.LayerNorm(d_model)
def forward(self, x, attn_mask=None):
batch_size, seq_len, d_model = x.shape
h_dim = d_model // self.n_head
assert h_dim * self.n_head == d_model
Q = self.Q(x).view(batch_size, seq_len, self.n_head, h_dim).permute(0,2,1,3)
K = self.K(x).view(batch_size, seq_len, self.n_head, h_dim).permute(0,2,1,3)
V = self.V(x).view(batch_size, seq_len, self.n_head, h_dim).permute(0,2,1,3)
if attn_mask is not None:
attn_mask = attn_mask.expand(batch_size, self.n_head, seq_len, seq_len) # Expanding to [batch_size, n_head, seq_len, seq_len]
# print(f"attn_mask shape after expansion: {attn_mask.shape}")
attn_score = self.scaled_dot_attn(Q, K, V, attn_mask)
attn_score = attn_score.permute(0,2,1,3).reshape(batch_size, seq_len, -1)
attn_score = self.dropout(attn_score)
attn_score = self.norm(attn_score + x)
return attn_score
Cross Attention
Cross Attention only modifies the input of Self Attention. The decoder of the Transformer is shown in the right module of the figure below:
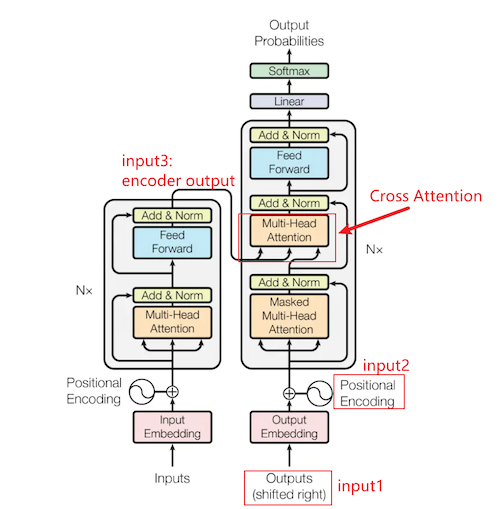
- With three inputs labeled as input1~3. The decoder recursively inputs input1: the output of the decoder from the previous time step (the first input is
<bos>, indicating the beginning of the sentence) - Adds it to input2: position encoding representing positional information, and performs cross attention with input3. Intuitively, what Cross Attention does is to use the information of key/value to represent the information of query, or to condition query on the condition of key/value. It can also be said to introduce the information of key/value into the information of query (because there is a residual layer that adds to the original query information), and what is obtained is the relevance of query to key (query attending to key, e.g., vehicle attending to lanes, vice versa).
-
In the decoder, the output is generated by first projecting the hidden state into a vector with the same size as the target vocabulary. This vector is then passed through a Softmax function to obtain a probability distribution over all possible tokens in the vocabulary. The token with the highest probability is typically selected as the output at each timestep. However, there are alternative strategies for token selection, such as beam search or sampling methods, which consider multiple high-probability candidates instead of always choosing the most probable token.
Heres the code for Corss-Head Attention, it could use the Multi-Head Attention code, but for clarity, i rewrote the class for Cross-Head Attention
class MultiHeadCrossAttn(nn.Module): def __init__(self, n_head, d_model, dropout=0.1): super(MultiHeadCrossAttn, self).__init__() self.n_head = n_head self.d_model = d_model self.head_dim = d_model // n_head assert self.head_dim * n_head == d_model, "d_model must be divisible by n_head" # Initialize linear layers for Q, K, V transformations self.query = nn.Linear(d_model, d_model) self.key = nn.Linear(d_model, d_model) self.value = nn.Linear(d_model, d_model) # Attention mechanism self.attention = ScaledProductAttn(dropout) # Layer norm and dropout self.dropout = nn.Dropout(p=dropout) self.norm = nn.LayerNorm(d_model) def forward(self, target, memory, attn_mask=None): # target is from decoder, memory is the encoder's output batch_size, target_len, _ = target.shape _, memory_len, _ = memory.shape # Project target and memory to query, key, value spaces Q = self.query(target).view(batch_size, target_len, self.n_head, self.head_dim).permute(0, 2, 1, 3) K = self.key(memory).view(batch_size, memory_len, self.n_head, self.head_dim).permute(0, 2, 1, 3) V = self.value(memory).view(batch_size, memory_len, self.n_head, self.head_dim).permute(0, 2, 1, 3) # Expand the attention mask if present if attn_mask is not None: attn_mask = attn_mask.expand(batch_size, self.n_head, target_len, memory_len) # Apply scaled dot product attention attn_output = self.attention(Q, K, V, attn_mask) attn_output = attn_output.permute(0, 2, 1, 3).contiguous().view(batch_size, target_len, self.d_model) # Apply dropout, add residual and norm output = self.dropout(attn_output) output = self.norm(output + target) return output
Encoder-decoder
Now we have encoder and decoder and we put them together
import torch
import torch.nn as nn
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, device):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def padding_mask(self, input):
input = input.to(self.device)
input_mask = (input != 0).unsqueeze(1).unsqueeze(2).to(self.device)
return input_mask
def target_mask(self, target):
target = target.to(self.device)
target_pad_mask = (target != 0).unsqueeze(1).unsqueeze(2).to(self.device) # shape(batch_size, 1, 1, seq_length)
target_sub_mask = torch.tril(torch.ones((target.shape[1], target.shape[1]), device=self.device)).bool() # shape(seq_len, seq_len)
target_mask = target_pad_mask & target_sub_mask # shape(batch_size, 1, seq_length, seq_length)
return target_mask
def forward(self, input, target):
input = input.to(self.device)
target = target.to(self.device)
input_mask = self.padding_mask(input)
target_mask = self.target_mask(target)
# encoder feed through
encoded_input = self.encoder(input, input_mask)
# decoder feed through
output = self.decoder(target, encoded_input, input_mask, target_mask)
return output
Padding Mask
Padding mask was used to mask the padded tokens in attention calculation
import torch
def create_padding_mask(input_seq, pad_token):
"""
Create a mask tensor to indicate the padding tokens in the input sequence.
"""
mask = (input_seq != pad_token).float()
return mask
# Example usage
batch_size = 2
seq_len = 5
pad_token = 0
input_seq = torch.tensor([[1, 2, 3, 0, 0],
[4, 5, 0, 0, 0]])
mask = create_padding_mask(input_seq, pad_token)python
'''
tensor([[1., 1., 1., 0., 0.],
[1., 1., 0., 0., 0.]])
'''
Subsequent Mask/ Look-ahead Mask
The subsequent mask is used in the decoder self-attention mechanism to prevent the model from attending to future positions during the decoding process. It ensures that the predictions for a given position can only depend on the known outputs at positions less than or equal to the current position.
Subsequent Mask:
tensor([[ True, False, False, False, False, False],
[ True, True, False, False, False, False],
[ True, True, True, False, False, False],
[ True, True, True, True, False, False],
[ True, True, True, True, True, False],
[ True, True, True, True, True, True]])
Masked Tokens at Each Time Step:
Time Step 1: I __ __ __ __ __
Time Step 2: I love __ __ __ __
Time Step 3: I love to __ __ __
Time Step 4: I love to code __ __
Time Step 5: I love to code in __
Time Step 6: I love to code in PyTorch
tensor([[ True, False, False, False, False, False],
[ True, True, False, False, False, False],
[ True, True, True, False, False, False],
[ True, True, True, True, False, False],
[ True, True, True, True, True, False],
[ True, True, True, True, True, True]])TrainingzLzpython
Training
Pytorch dataset & dataloader
class MyDataset(Dataset):
def __init__(self, data):
self.src_lang = data['src']
self.tgt_lang = data['tgt']
def __len__(self):
return len(self.src_lang)
def __getitem__(self, index):
return {
'src': self.src_lang[index],
'tgt': self.tgt_lang[index]
}
def collate_fn(batch):
src_batch = [item['src'] for item in batch]
tgt_batch = [item['tgt'] for item in batch]
#padding
src_batch_padded = pad_sequence([torch.tensor(x, dtype=torch.long) for x in src_batch], batch_first=True, padding_value=0)
tgt_batch_padded = pad_sequence([torch.tensor(x, dtype=torch.long) for x in tgt_batch], batch_first=True, padding_value=0)
return {
'src': src_batch_padded,
'tgt': tgt_batch_padded,
}
# Create instances of MyDataset
train_dataset = MyDataset(train_data)
validation_dataset = MyDataset(validation_data)
# Create data loaders
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=collate_fn)
validation_loader = DataLoader(validation_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
Training
Save the checkpoints
# Setup TensorBoard writer and device
writer = SummaryWriter()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Initialize model components
num_layers = 6
num_heads = 8
d_model = 512
d_ff = 1024
encoder = Encoder(vocab_size=10000, n_layer=num_layers, n_head=num_heads, d_model=d_model, d_ff=d_ff)
decoder = Decoder(vocab_size=10000, n_layer=num_layers, n_head=num_heads, d_model=d_model, d_ff=d_ff)
model = EncoderDecoder(encoder, decoder, device).to(device)
# Setup training essentials
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5)
scheduler = StepLR(optimizer, step_size=5, gamma=0.5)
scaler = GradScaler()
# Training loop
EPOCHS = 30
checkpoints_dir = '../checkpoints'
os.makedirs(checkpoints_dir, exist_ok=True)
best_vloss = float('inf')
for epoch in range(EPOCHS):
print(f'EPOCH {epoch + 1}:')
epoch_avg_loss = train_one_epoch(train_loader, epoch, writer, model, optimizer, criterion, scaler, device)
print(f'Average Training Loss: {epoch_avg_loss:.2f}')
avg_vloss = validate(validation_loader, model, criterion, device)
print(f'Validation Loss: {avg_vloss:.2f}')
writer.add_scalars('Training vs. Validation Loss', {'Training': epoch_avg_loss, 'Validation': avg_vloss}, epoch + 1)
writer.flush()
if avg_vloss < best_vloss:
best_vloss = avg_vloss
model_filename = os.path.join(checkpoints_dir, f'model_epoch_{epoch + 1}.pt')
torch.save(model.state_dict(), model_filename)
print(f'Model saved: {model_filename}')
scheduler.step()
print(f"Learning Rate: {scheduler.get_last_lr()}")
torch.cuda.empty_cache()
writer.close()
Inference
def translate(src_sentence, model, sp, max_length=10):
model.eval()
# Tokenize the source sentence
src_tokens = sp.encode_as_ids(src_sentence)
src_tensor = torch.LongTensor(src_tokens).unsqueeze(0).to(device)
with torch.no_grad():
src_mask = model.padding_mask(src_tensor)
memory = model.encoder(src_tensor, src_mask)
trg_indexes = [sp.bos_id()]
for _ in range(max_length):
trg_tensor = torch.LongTensor(trg_indexes).unsqueeze(0).to(device)
trg_mask = model.target_mask(trg_tensor)
with torch.no_grad():
output = model.decoder(trg_tensor, memory, src_mask, trg_mask)
pred_token = output.argmax(2)[:, -1].item()
trg_indexes.append(pred_token)
if pred_token == sp.eos_id():
break
trg_tokens = sp.decode_ids(trg_indexes)
return trg_tokens
#Initialize the model and import the tokenizer and checkpoint with the best performance
num_layers = 6
num_heads = 8
d_model = 512
d_ff = 1024
encoder = Encoder(vocab_size=10000, n_layer=num_layers, n_head=num_heads, d_model=d_model, d_ff=d_ff)
decoder = Decoder(vocab_size=10000, n_layer=num_layers, n_head=num_heads, d_model=d_model, d_ff=d_ff)
model = EncoderDecoder(encoder, decoder, device).to(device)
model_path = os.path.join(parent_dir, 'checkpoints', src_lang + '-' + tgt_lang, 'model.pt')
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
model.eval()
spm_model_path = os.path.join(parent_dir, 'data', src_lang + '-' + tgt_lang, 'bpe', 'bpe.model')
sp = spm.SentencePieceProcessor(model_file=spm_model_path)
translated_sentence = translate(src_sentence, model, sp)
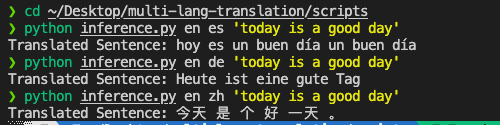
Translate Examples
Heres the examples of translating english into Spanish, German and Chinese